
Another day, another episode of #TheEmailThatBecameABlogPost. Today, how can we include business sensitive image files in Power BI Paginated Reports?
The Problem
Images in Paginated Reports can be sourced from three locations: embedded in the report, from a public URL or from a dataset/database. Static embedded images are great for design content - logos, backgrounds. Static images can also be retrieved from a public webserver and URLs can be data-bound, allowing us to include dynamic images. Obviously, hosting images behind a publicly available endpoint is not really desirable for sensitive content, which leaves the final option - images as part of the dataset read from the backend source.
Storing images in a data lake is pretty common, but how can we make these available to our reports? (Besides exposing the underlying storage container to the public internet which is Not A Good Idea™).
If only there was an easy way to read these image files and serve them up through a SQL endpoint? If only….
Keeping It Real, SQL style
The particular data lake in question centred around Azure Databricks and Azure Data Lake Storage, with Power BI Premium for downstream reporting (similar to Modern analytics architecture with Azure Databricks). This gives us a few options to hook into.
Paginated Reports are cool, but are somewhat limited in supported datasources. We could hook up our paginated to a regular Power BI dataset which would allow us to connect directly to ADLS, Databricks or any of the other zillionty supported sources to retrieve our photos. But plot twist, we’re dealing with relatively high-res, largish files and there’s that pesky 2.1M character DAX limit. And besides, it feels a bit sketchy using a dataset to work around the lack of a connector. Having said that, it’s a perfectly valid approach if Paginated and vanilla Reports are consuming the same data, but that’s not the case here.
Since we already have a SQL engine available in Databricks, lets see how we can use that to serve up our images (and some associated data). I do ❤️ an OG SQL solution.
Test Data
First I grabbed some images from Pexels (which is where all of my blog pics come from btw) and uploaded to my ADLS2 storage account:
I also created a very small csv of comments - one for each pic.
id,filename,comment
1,pexels-chevanon-photography-312418.jpg,Classic Cappucino
2,pexels-olof-nyman-1710023.jpg,That's not espresso
3,pexels-andrew-neel-4264049.jpg,Another not espresso
4,pexels-lood-goosen-1235706.jpg,Definitely not espresso
The Code
My demo cluster is setup to use a Service Principal to access my storage with a secret backed by Key Vault. There are a number of other ways to configure ADLS2 access.
A quick side note my cluster config props:
fs.azure.account.auth.type OAuth fs.azure.account.oauth.provider.type org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider fs.azure.account.oauth2.client.id <your-service-principal-id> fs.azure.account.oauth2.client.secret {{secrets/<secret-scope>/<secret-name>}} fs.azure.account.oauth2.client.endpoint https://login.microsoftonline.com/<your-tenant-id>/oauth2/tokenIf you know, you know…
Reading Images From ADLS2
We can try reading our images using binaryFile data source (https://learn.microsoft.com/en-us/azure/databricks/external-data/binary):
df = spark.read.format("binaryFile").load("abfss://<your-container-name>@<your-storage-account-name>.dfs.core.windows.net/images")
display(df)
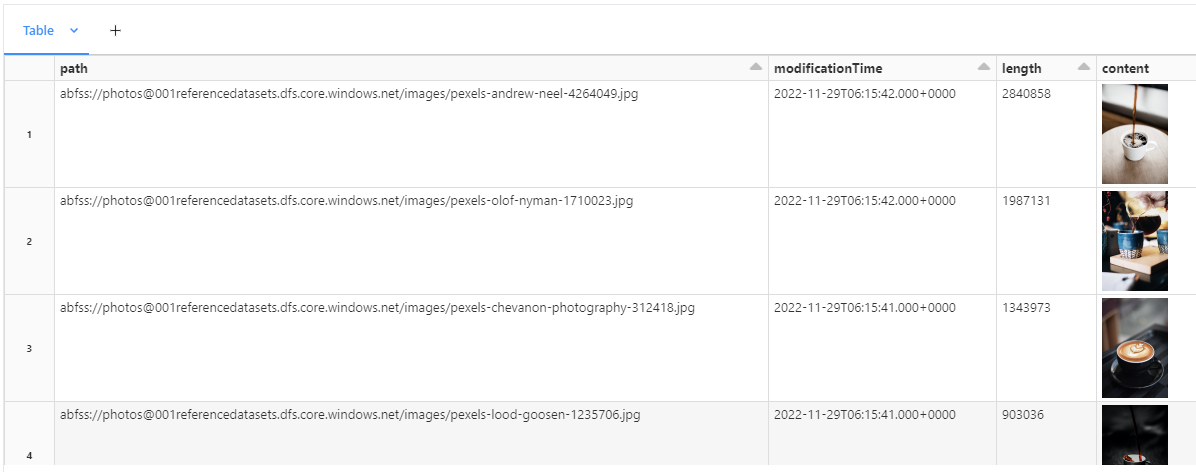
We have coffee 😄
We can do the same in SQL:
%sql
SELECT * FROM binaryFile.`abfss://<your-container-name>@<your-storage-account-name>.dfs.core.windows.net/images`
which returns exactly the same result.
Create Some Tables
Let’s make some tables (there’s a joke in there about coffee tables but let’s not).
CREATE Table Comments (
Id LONG,
Filename STRING,
Comment STRING
) USING CSV
LOCATION 'abfss://<your-container-name>@<your-storage-account-name>.dfs.core.windows.net/Coffees.csv'
OPTIONS (header 'true');
CREATE Table Photos (
path STRING,
modificationTime TIMESTAMP,
length LONG,
content BINARY
)
USING BINARYFILE
LOCATION 'abfss://<your-container-name>@<your-storage-account-name>.dfs.core.windows.net/images'
Cool. Now to join these two tables together on filename and create a view for our report:
CREATE OR REPLACE VIEW ReportView AS
SELECT
C.Filename,
C.Comment,
P.Content
FROM Comments C
JOIN (
SELECT
split_part(path,"/", -1) Filename,
Content
FROM Photos) P
ON C.Filename = P.Filename
The Paginated Report
ODBC
We’ll need to install and configure the DataBricks ODBC driver https://docs.databricks.com/integrations/jdbc-odbc-bi.html. For testing, I also used a personal access token
Here’s the connection string formed from copying the config as per the ODBC doco:
Driver=Simba Spark ODBC Driver;host=abd-XXXXXXX.azuredatabricks.net;port=443;httppath=<http-path>;thrifttransport=2;ssl=1;authmech=3;UID=token;PWD=<your-token>
Build the Report
First, install Power BI Report Builder.
Create a new datasource, with the connection string from above. Test the connection.
Next create a new dataset and select the contents of the view we created previously
Add a table to the report and drag the Comment field onto the first column
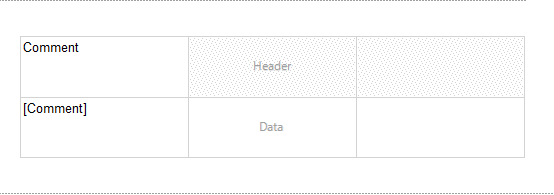
Right click on an empty cell and insert an image
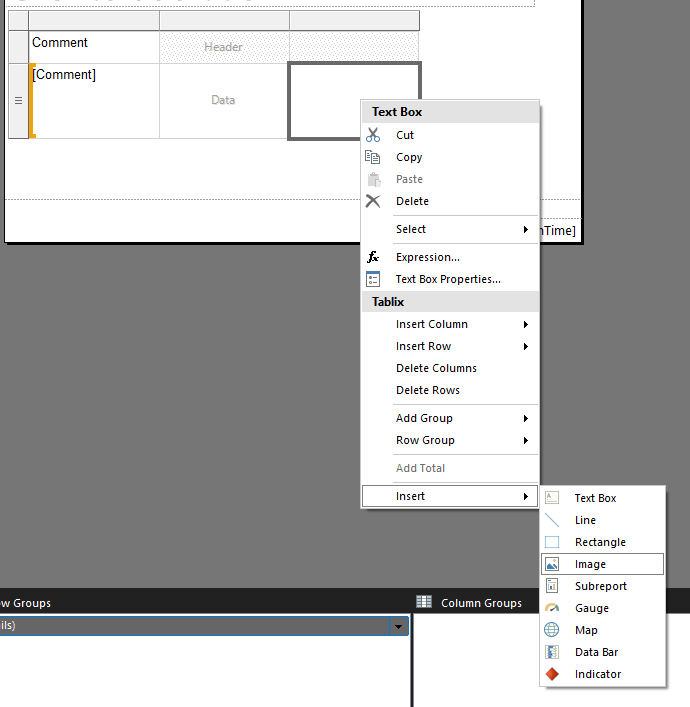
Set the properties to
- Source: Database
- Field: Content
- MIME Type: Well, we’re not returning mime type in our query, and the test images are all jpegs so…
At this point you can run the report, or make it look pretty. Guess which I chose?
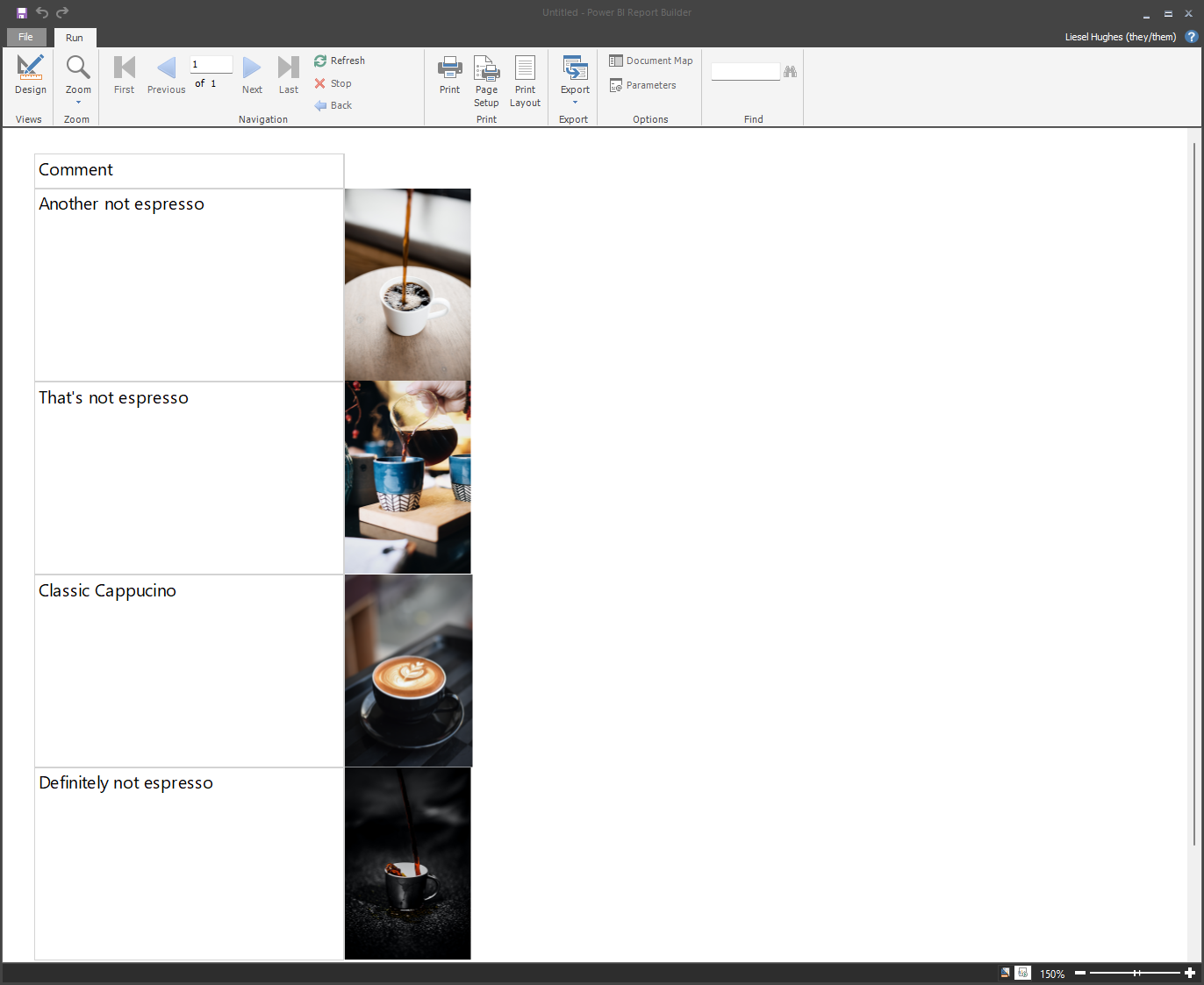
Wrapping Up
And there you have it, serving up hot cups of stuff that’s not exactly coffee (and a cap) from Azure Data Lake Storage with a little help from Azure Databricks.